Static Application Security Testing (SAST): The Good, the Bad, and the Ugly
Static Application Security Testing (SAST) promises early vulnerability detection directly from source code. But how effective is it in practice? This guide explores where SAST tools excel, where modeling and rule-based detection break down, and what security and engineering teams should realistically expect from static analysis.
Static Application Security Testing (SAST) refers to tools that analyze source code to identify potential security vulnerabilities without executing the application. One application analyzes another and flags suspicious patterns for review. SAST promises early detection, automation, and scalability. In practice, it delivers real value alongside real frustration.
This is a sober look at what SAST does well, where it falls short, and what engineering leaders should realistically expect from it inside a modern SDLC — including how the explosion of AI-generated code has fundamentally raised the stakes.
What SAST Is (And How It Actually Works)
At its core, a SAST tool performs two major functions: modeling the software, and applying rules to detect vulnerability patterns.
Modern SAST engines invest heavily in code modeling. That modeling typically includes lexical analysis, Abstract Syntax Trees (AST), data flow graphs, interprocedural call graphs, and taint tracking across execution paths.
On top of that model, vendors create rule sets designed to detect common vulnerability classes, typically aligned to benchmarks such as the OWASP Top 10 and the SANS/CWE Top 25 Software Errors. In theory, this delivers structured, repeatable vulnerability detection directly from source code before deployment.
The Case for SAST
There is a reason SAST remains a staple in secure DevSecOps pipelines.
SAST analysis is extremely efficient: it runs statically against source code, offline, without a running environment. Modern tools have evolved well beyond simple pattern matching. Leading platforms such as Checkmarx, Semgrep, Snyk Code, and SonarQube now embed directly into IDEs and CI/CD pipelines, delivering inline feedback at the pull request level without disrupting development velocity.
SAST also supports compliance. Frameworks including PCI DSS v4.0, HIPAA, and ISO 27001 require organizations to demonstrate that security is integrated into the development process. SAST provides the audit trails, dashboards, and reporting that make those requirements demonstrable.
Beyond vulnerability detection, good SAST tooling also flags poor coding practices that contribute to technical debt, helping teams formalize secure coding standards and reduce future rework.
The AI-Generated Code Problem
There is a dimension to this discussion that has become impossible to ignore: AI coding assistants. Tools like GitHub Copilot, Cursor, and Claude Code are now contributing a significant volume of enterprise code. The speed gains are real. So are the risks.
Veracode's 2025 GenAI Code Security Report tested over 100 LLMs across Java, JavaScript, Python, and C# and found that AI-generated code contains substantially more vulnerabilities than human-written code, with roughly 45% of AI-generated samples introducing OWASP Top 10 vulnerabilities. Cross-Site Scripting failures were found in over 86% of tested cases, and Java showed a 72% security failure rate for AI-generated code.
Independent research from Apiiro looking at Fortune 50 enterprises found that AI-generated code produced significantly more privilege escalation paths, more design flaws, and a notable jump in secrets exposure compared to human-authored code.
The implication for SAST is direct: if your developers are using AI assistants, your volume of code requiring scanning has grown dramatically. More code, more risk, more findings per unit of time. SAST is no longer optional in this environment. It needs to be automatic, embedded, and running on every commit.
Where SAST Struggles
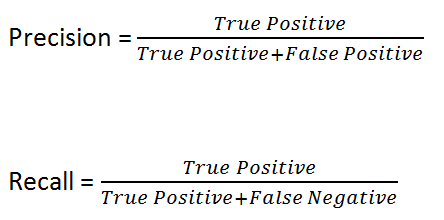
Anyone who has used a modern static analysis tool knows the rules are not perfect. The SAST industry measures tool effectiveness using two metrics: precision (the fraction of reported findings that are true positives) and recall (the fraction of actual vulnerabilities that are detected). Neither can be assumed to be high without evidence.
An initial scan of a medium-sized project can return thousands of findings. That raises three uncomfortable questions:
- Are there really that many vulnerabilities in this codebase?
- What is the precision of these findings?
- What confidence can we have that recall is sufficient?
The answer to the third question is: none, by default. Here is why.
Modeling Limitations
SAST modeling is inherently constrained because it only accounts for source code. Vulnerabilities can be exposed not just by application logic, but by system configuration, infrastructure setup, and deployment environment. None of that is visible to a static analyzer.
Data flows that cross technology boundaries are particularly difficult to model. Consider a simple web application where a user submits data via an HTTP POST, that data is stored in a database, and later retrieved and rendered by a different service. The two code paths are disconnected through the database layer. Questions that naturally arise include: was the data sanitized on insert? Was it sanitized for the correct consumer context, whether HTML, JSON, or XML? Was it sanitized on retrieval before being sent to the client? SAST tools have limited visibility into these cross-boundary flows.
Server configuration and access control present similar challenges. Authentication logic can be implemented in an infinite number of ways depending on product requirements. At best, SAST tooling takes a pattern-matching approach here, which means business logic violations and authorization flaws regularly slip through.
Where SAST Performs Well vs. Where It Struggles
Strong detection:
- Cross-Site Scripting (XSS)
- SQL Injection
- Cross-Site Request Forgery (CSRF)
- Insecure logging practices
- Information leakage
- XML External Entity (XXE) Injection
- Insecure deserialization
Weaker detection:
- Insecure access control and authorization flaws
- Cross-Origin Resource Sharing (CORS) misconfigurations
- Insecure direct object references
- Business logic vulnerabilities
- AI-specific patterns such as hallucinated dependency injection (sometimes called slopsquatting)
The last category is a newer concern. AI coding assistants sometimes suggest non-existent packages. Developers who integrate them without verification create supply chain risk, and traditional SAST tooling is not designed to detect this class of issue.
How Engineering Teams Can Make SAST More Effective
Rather than asking whether SAST is good or bad, the more useful question is: how do we reduce noise and increase signal?
1. Calibrate Rulesets for Your Context
Out-of-the-box ruleset precision is measured against generic benchmarks, not your codebase. Teams should disable noisy categories that do not apply to their stack, tune thresholds, and prioritize high-confidence findings first. Vendor benchmarks and your specific codebase will diverge, and the gap is often significant.
2. Embed Scanning Directly in the Developer Workflow
Effective SAST is not a weekly batch scan. Modern tools should run on every commit and every pull request, with findings surfaced inline in the IDE or code review interface. Tools like Semgrep, Snyk Code, and GitLab SAST support this pattern natively. The closer findings are to the moment of code creation, the cheaper they are to fix.
This is especially important for AI-generated code. As Veracode and others have noted, scaling model size does not organically improve the security of AI output. The organizations that manage this risk successfully will be those that build robust automated scanning systems around their AI-assisted workflows, not those waiting for the models to improve.
3. Treat SAST as Hygiene, Not Assurance
SAST improves baseline security hygiene. It does not prove a system is secure. Engineering leaders who communicate this distinction clearly will build more realistic and resilient security programs. A clean SAST scan means suspicious patterns were not found in source code. It says nothing about configuration, runtime behavior, or business logic correctness.
4. Invest in Developer Education
Repeated findings often trace back to misunderstood frameworks, improper input handling, and unsafe dependency usage. Better education reduces findings at their source. This now includes educating developers on how to write security-focused prompts when using AI assistants, and how to critically evaluate AI-generated code rather than committing it without review.
5. Layer SAST Within a Broader Security Program
SAST covers one dimension of a multi-dimensional problem. It works best as part of a layered approach:
- SAST for source-level pattern detection
- SCA (Software Composition Analysis) for third-party and AI-suggested dependency risk
- DAST (Dynamic Application Security Testing) for runtime and authentication flow validation
- IaC scanning for infrastructure configuration
- Code review for business logic and architectural intent
- Runtime monitoring for production behavior
No single control is sufficient. SAST is not meant to carry the program alone.
Choosing a SAST Tool: What to Evaluate
As of the current market, leading enterprise SAST tools include Checkmarx, Veracode, Semgrep, Snyk Code, SonarQube, and ZeroPath, among others. Newer entrants are competing specifically on AI-generated code coverage and false positive reduction.
When evaluating tools, prioritize:
- Language and framework coverage aligned to your actual stack, not a generic list
- Cross-file analysis and data flow tracking, not just line-level pattern matching
- CI/CD and IDE integration for scan latency and developer adoption
- AI-generated code support, since many older SAST engines were not designed for the volume or patterns AI assistants produce
- Precision and recall benchmarks, ideally tested against a sample of your own codebase rather than generic benchmarks
- Compliance reporting if your organization operates under PCI DSS, HIPAA, SOC 2, or similar frameworks
- On-premises deployment options for teams with strict data residency requirements
Note also that Veracode's 2025 data shows the average time to fix half of all outstanding vulnerabilities is 252 days. Mean time to remediate (MTTR) is increasingly a core operational metric. Your SAST tooling should support SLA tracking and MTTR visibility, not just finding generation.
Final Thoughts
SAST excels at detecting repeatable, pattern-based vulnerabilities in source code. It struggles with context-heavy, configuration-driven, and business-logic flaws. Its effectiveness depends heavily on precision, recall, and how closely your code aligns with vendor benchmarks — a gap that has widened as AI-generated code introduces new vulnerability patterns that traditional scanning was not designed to catch.
The operational context has also shifted. AI coding assistants are now contributing a material share of enterprise code, and that code carries measurably higher vulnerability rates than human-authored code. Engineering leaders who treat SAST as a set-and-forget checkbox are creating the conditions for false confidence. Those who treat it as a continuously tuned, deeply embedded signal within a layered security program will get genuine value from it.
Used thoughtfully, SAST reduces risk and improves baseline hygiene. Used blindly, it creates noise and false confidence. The real value of SAST is not that it makes your application secure. It is that it makes insecure patterns harder to ignore early in the development process. And in modern software development, early matters more than ever. SAST is a useful first filter, but it can't replicate what a skilled tester finds when they interact with your running application. If you're using SAST as your primary security gate, pairing it with a web application penetration test gives you the coverage SAST can't provide like logic flaws, chained vulnerabilities, and context-dependent issues that static analysis consistently misses.
Ready to get in touch? Get started by booking a consultation now.
About the author
.avif)
Sherif Koussa
CEO
Sherif Koussa is a cybersecurity expert and entrepreneur with a rich software building and breaking background. In 2006, he founded the OWASP Ottawa Chapter, contributed to WebGoat and OWASP Cheat Sheets, and helped launch SANS/GIAC exams. Today, as CEO of Software Secured, he helps hundreds of SaaS companies continuously ship secure code.



